
DeepSeek V4 更多细节曝光,最快下周发布
DeepSeek V4 更多细节曝光,最快下周发布科技账号 Legit 率先披露,V4 的轻量版本代号为「sealion-lite(海狮轻量版)」,目前已在至少一家推理服务商处展开内测,相关方均签署了严格的保密协议。
来自主题: AI资讯
9796 点击 2026-02-26 10:37
 搜索
搜索
科技账号 Legit 率先披露,V4 的轻量版本代号为「sealion-lite(海狮轻量版)」,目前已在至少一家推理服务商处展开内测,相关方均签署了严格的保密协议。

机器之心编译 如果把人生看作一个开放式的大型多人在线游戏(MMO),那么游戏服务器在刚刚完成一次重大更新的时刻,规则改变了。 自 2022 年 ChatGPT 惊艳亮相以来,世界已经发生了深刻变化。在
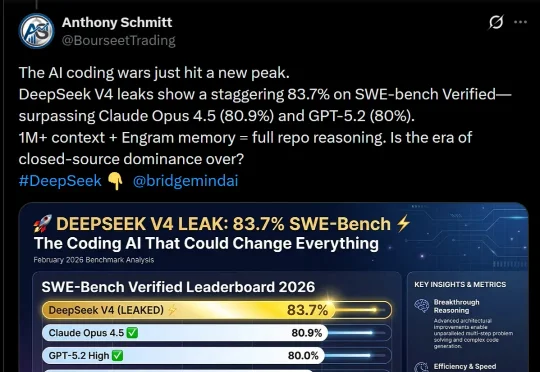
DeepSeek V4,据说明天就要上线了?这是首个匹敌顶尖闭源模型的开源模型,被网友评为「一鲸落万物生」。泄露的基准测试显示,它在SWE-bench Verified上取得了83.7%,已经超越Opus 4.5和GPT-5.2!

确认了!DeepSeek昨晚官宣网页版、APP更新,支持100k token上下文。如今,全网都在蹲DeepSeek V4了。
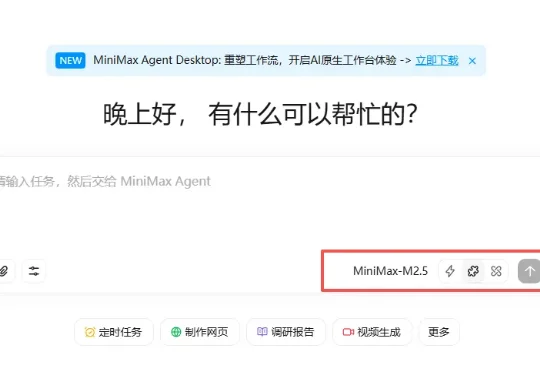
这两天 AI 圈真的太热闹了,就在网传 DeepSeek 要更新支持 100 万 Token 上下文的新模型时,MiniMax 率先冲锋,更新了他们的新旗舰模型:MiniMax-M2.5。更有意思的是,国外网友这段时间对国内 AI 大模型的更新节奏格外关注,他们甚至把这种争先更新的现象称为:Happy Chinese new year!
春节还没到,「过年的气氛」已经渗入科技圈每个人的毛孔。单说 AI 大模型这一块,刚刚发布的有 kimi 2.5 和 Step 3.5 Flash,即将发布的据说还有 DeepSeek V4,GPT-5.3、Claude Sonnet 5、Qwen 3.5,GLM-5,说不定一觉醒来,现有的技术就要被颠覆。
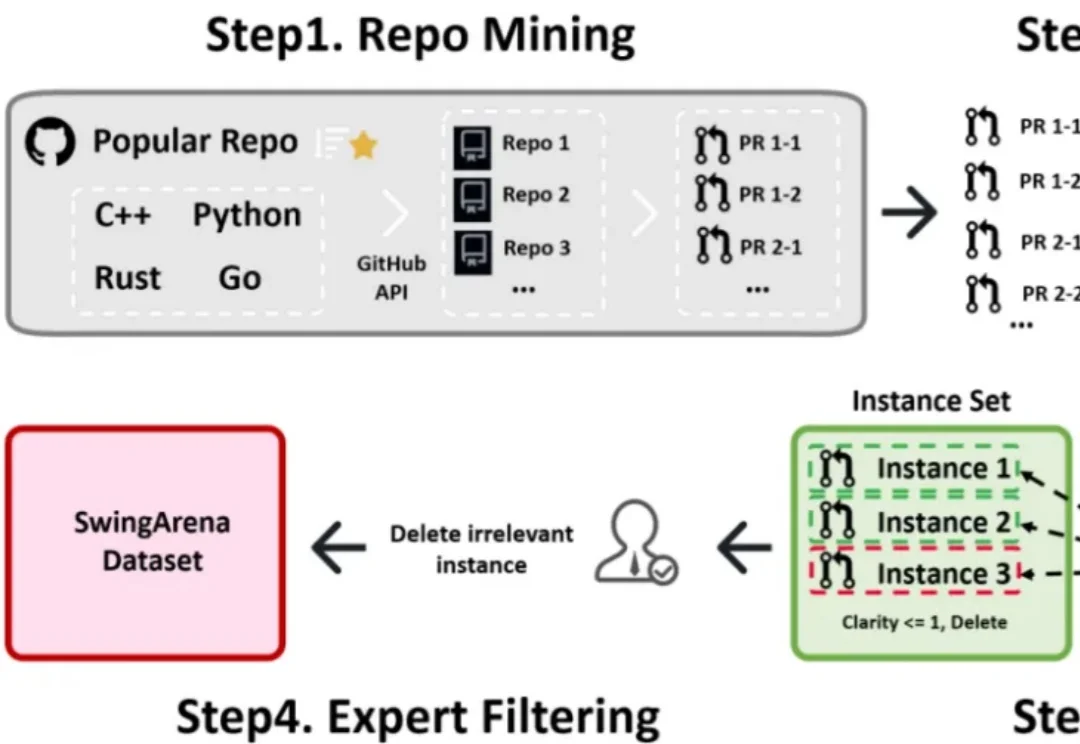
过去一年,大模型写代码的能力几乎以肉眼可见的速度提升。从简单脚本到完整功能模块,GPT、Claude、DeepSeek 等模型已经能够在几秒钟内生成看起来相当 “专业” 的代码。
春节假期还没到,DeepSeek 就先把礼物拆了一半。

以DeepSeek R1为代表的一系列基于强化学习(RLVR)微调的工作,显著提升了大语言模型的推理能力。但在这股浪潮背后,强化微调的代价却高得惊人。

2025 年 1 月 20 日,DeepSeek 发布了推理大模型 DeepSeek-R1,在学术界和工业界引发了对大模型强化学习方法的广泛关注与研究热潮。 研究者发现,在数学推理等具有明确答案的任务